Python机器学习作者科普长文:从头构建类GPT文本分类器
近日,Sebastian Raschka 又分享了一篇长文,主题为《从头开始构建一个 GPT 风格的 LLM 分类器》。

文章展示了如何将预训练的大型语言模型(LLM)转化为强大的文本分类器。机器之心对文章内容进行了不改变原意的编译、整理:
为什么要关注分类呢?首先,针对分类任务,对预训练模型进行微调是一个简单有效的 LLM 知识入门方式。其次,文本分类有许多商业应用场景,比如:垃圾邮件检测、情感分析、客户反馈分类、主题分类等等。
阅读完本文,你将找到以下 7 个问题的答案:
1. 需要训练所有层吗?
2. 为什么微调最后一个 token,而不是第一个 token?
3. BERT 与 GPT 在性能上有何比较?
4. 应该禁用因果掩码吗?
5. 扩大模型规模会有什么影响?
6. LoRA 可以带来什么改进?
7. Padding 还是不 Padding?
完整代码可以从 GitHub 找到:https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/ch06.ipynb
Different categories of finetuning
微调的不同种类
指令微调和分类微调是最常见的语言模型微调方法。指令微调是用特定任务训练模型,提高它理解和执行自然语言提示中所描述任务的能力,如下图 1 所示。
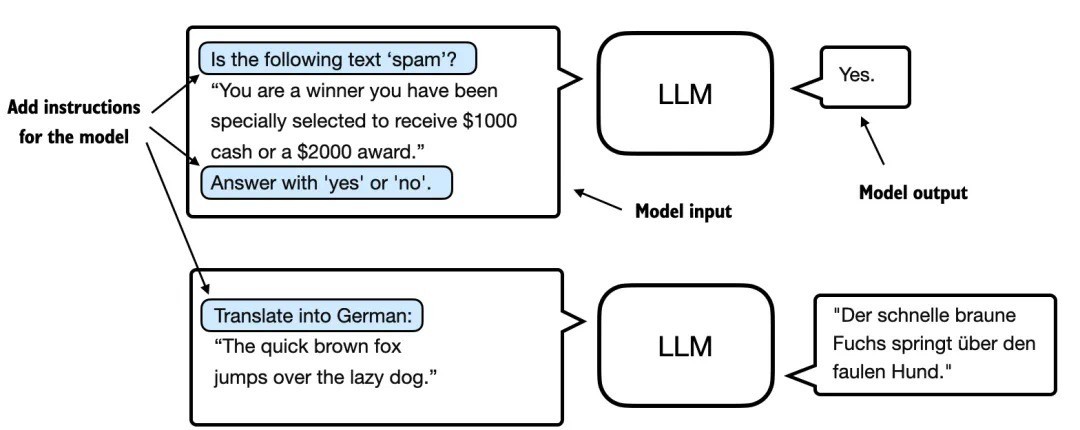
图 1:指令微调的两种场景。上方:模型的任务是判断文本是否为垃圾邮件;下方:模型的任务是将英文句子翻译成德语。
在分类微调中,模型被训练用于识别特定的类别标签,比如「垃圾邮件」和「非垃圾邮件」。分类任务还包括从图像中识别不同的植物、给新闻按体育、政治或科技等主题分类,从医学影像中区分良性和恶性肿瘤等等。
不过经过分类微调的模型只能判断类别,不能对输入的文本作出其他判断。
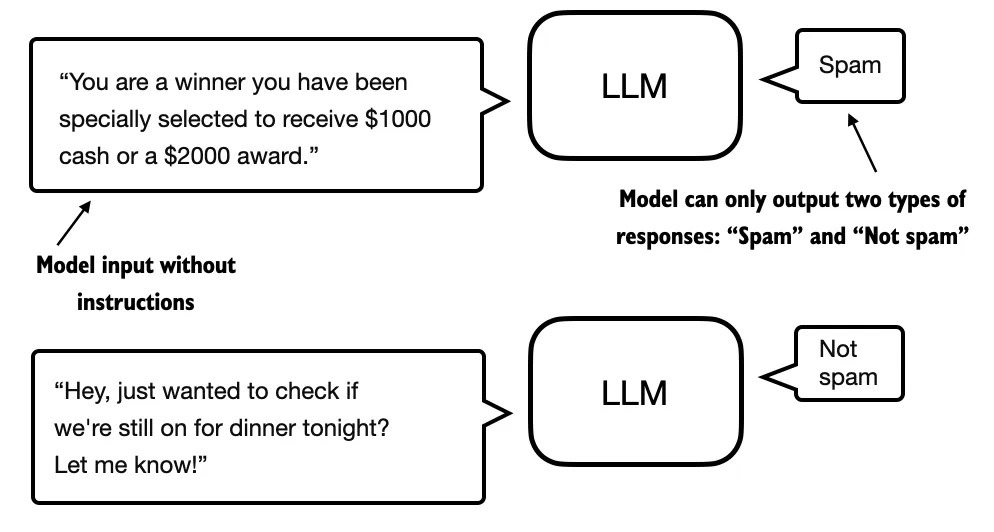
图 2:一个使用 LLM 进行垃圾邮件分类的示例。针对垃圾邮件分类微调的模型在输入时不需要额外的指令,然而,与指令微调模型相比,它的回答只能是「垃圾邮件」和「非垃圾邮件」。
指令微调的模型通常能够执行更广泛的任务。我们可以将分类微调的模型视为是高度专业化的模型,一般来说,开发一个专用模型比开发一个在各种任务上表现良好的通用模型更容易。
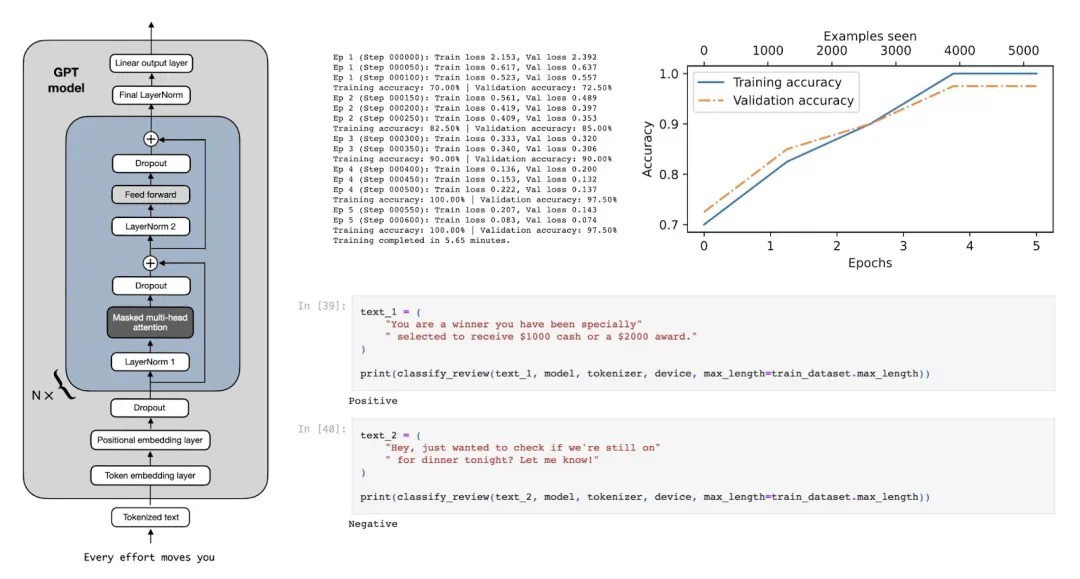
使用预训练权重初始化模型
下图中展示了将通用预训练 LLM 转变为专门用于分类任务的 LLM 需要做的修改:
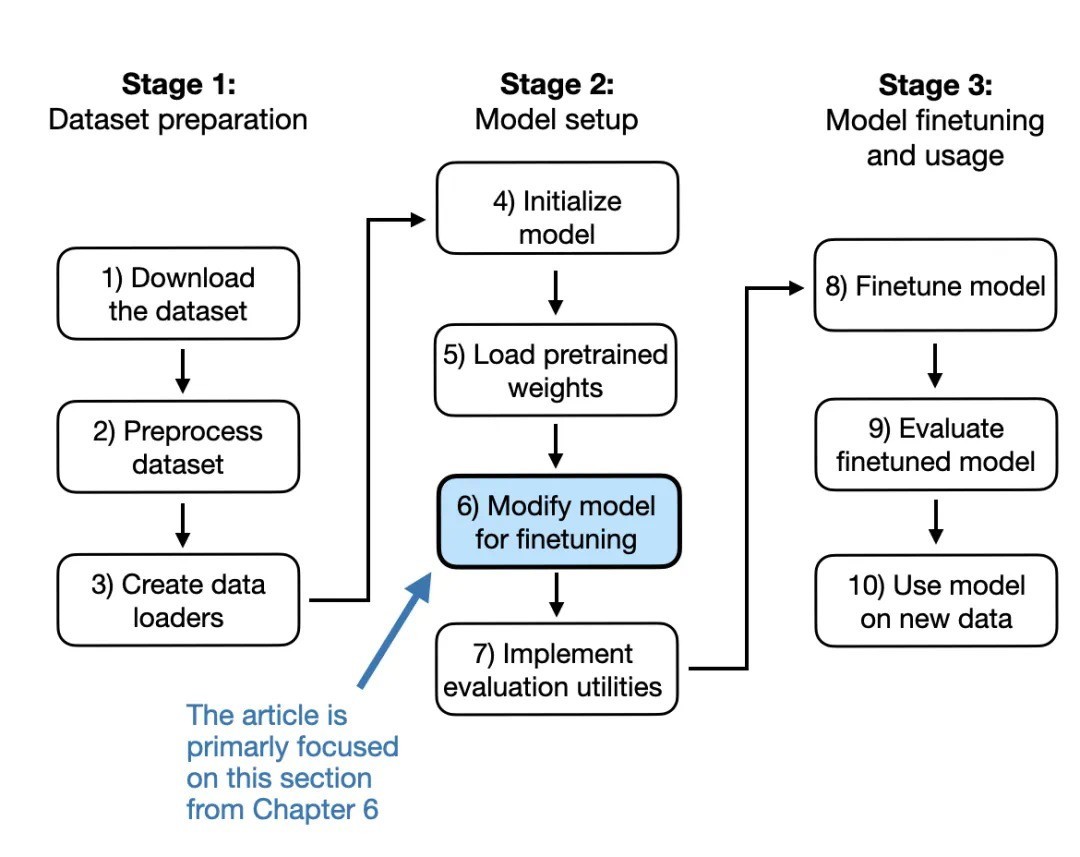
图 3:在此跳过步骤 1-5,直接进入步骤 6(将在下一节开始)。
在做修改之前,让我们先简单了解一下正在使用的预训练 LLM。为简便起见,假设我们设置了如下代码来加载该模型:
model = GPTModel (BASE_CONFIG) load_weights_into_gpt (model, params) model.eval ()
在将模型权重加载到 GPT 后,使用下列文本生成的函数库,确保模型生成连贯的文本:
from chapter04 import generate_text_simple from chapter05 import text_to_token_ids, token_ids_to_text text_1 = "Every effort moves you" token_ids = generate_text_simple ( model=model, idx=text_to_token_ids (text_1, tokenizer), max_new_tokens=15, context_size=BASE_CONFIG ["context_length"] ) print (token_ids_to_text (token_ids, tokenizer))
根据以下输出,我们可以看到模型生成了连贯的文本,这表明模型权重已正确加载:
Every effort moves you forward. The first step is to understand the importance of your work
让我们先看看模型是否可以通过指令微调完成垃圾邮件的分类:
text_2 = ( "Is the following text'spam'? Answer with 'yes' or 'no':" "'You are a winner you have been specially" "selected to receive $1000 cash or a $2000 award.'" ) token_ids = generate_text_simple ( model=model, idx=text_to_token_ids (text_2, tokenizer), max_new_tokens=23, context_size=BASE_CONFIG ["context_length"] ) print (token_ids_to_text (token_ids, tokenizer))
模型的输出如下所示:
Is the following text'spam'? Answer with 'yes' or 'no': 'You are a winner you have been specially selected to receive $1000 cash or a $2000 award.' The following text'spam'? Answer with 'yes' or 'no': 'You are a winner
可以明显看出模型在准确遵循指令方面遇到了一些挑战。这是可以预见的,因为它仅经过了预训练,缺乏指令微调。
加入分类头
我们将原始输出层(这层的功能是将模型内部生成的隐藏表示转换为一个包含 50,257 个 tokens 的词表)替换为一个较小的输出层,该层映射到两个类别:0(非垃圾邮件)和 1(垃圾邮件),如下图 4 所示。
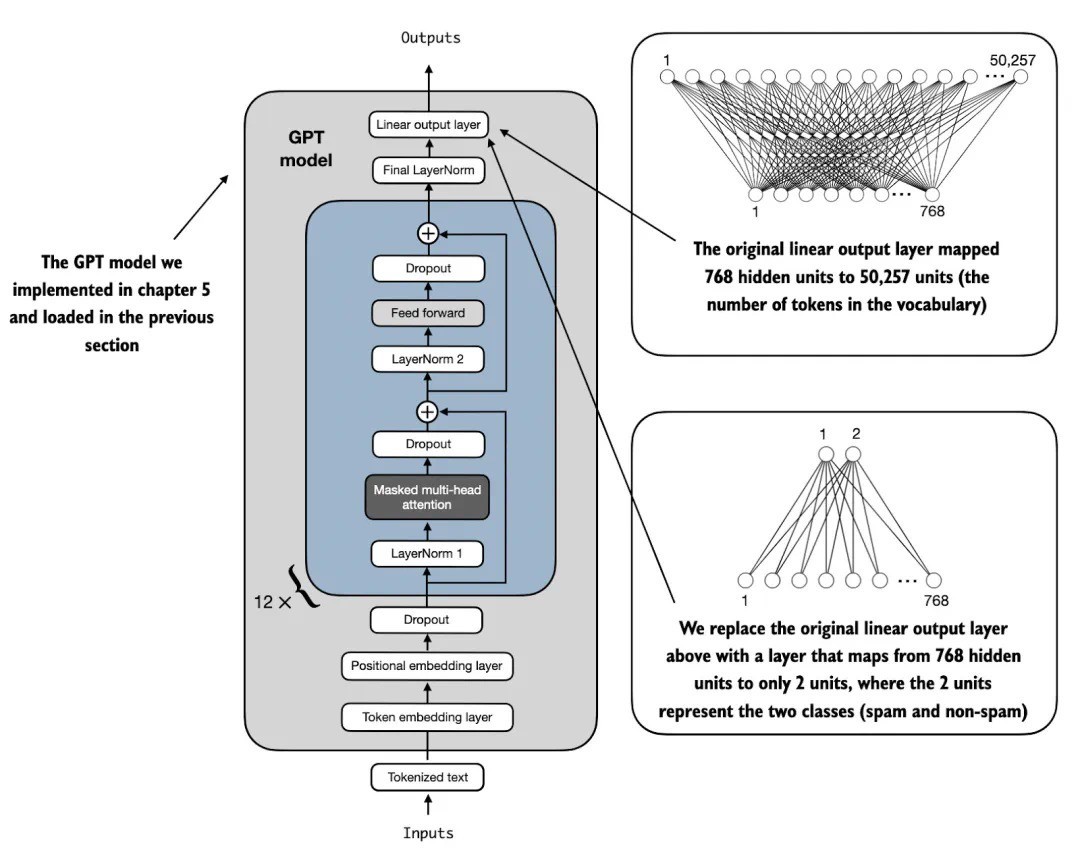
图 4:此图展示了如何通过改变架构将 GPT 模型适配为垃圾邮件分类。最初,模型的线性输出层将 768 个隐藏单元映射到一个包含 50,257 个 tokens 的词汇表。为了进行垃圾邮件检测,这一层被替换为一个新的输出层,该层将相同的 768 个隐藏单元映射到两个类别,分别表示「垃圾邮件」和「非垃圾邮件」。
输出层节点
从技术上讲,因为这是一个二元分类任务,可以只用一个输出节点。然而,这将需要修改损失函数。因此,我们选择一种更通用的方法,匹配输出节点与分类的数量。例如,对于一个分三类的问题,如将新闻文章分类为「科技」、「体育」或「政治」,使用三个输出节点,依此类推。
在尝试进行图 4 中所示的修改之前,先通过 print (model) 输出模型架构:
GPTModel ( (tok_emb): Embedding (50257, 768) (pos_emb): Embedding (1024, 768) (drop_emb): Dropout (p=0.0, inplace=False) (trf_blocks): Sequential ( ... (11): TransformerBlock ( (att): MultiHeadAttention ( (W_query): Linear (in_features=768, out_features=768, bias=True) (W_key): Linear (in_features=768, out_features=768, bias=True) (W_value): Linear (in_features=768, out_features=768, bias=True) (out_proj): Linear (in_features=768, out_features=768, bias=True) (dropout): Dropout (p=0.0, inplace=False) ) (ff): FeedForward ( (layers): Sequential ( (0): Linear (in_features=768, out_features=3072, bias=True) (1): GELU () (2): Linear (in_features=3072, out_features=768, bias=True) ) ) (norm1): LayerNorm () (norm2): LayerNorm () (drop_resid): Dropout (p=0.0, inplace=False) ) ) (final_norm): LayerNorm () (out_head): Linear (in_features=768, out_features=50257, bias=False) )
如上所示,GPTModel 由嵌入层和 12 个相同的 transformer 块组成,为简洁起见,仅显示最后一个块,然后是最终的 LayerNorm 和输出层 out_head。
接下来,我们将 out_head 替换为一个新的输出层,如图 4 所示,我们将对这一层进行微调。
选择微调特定层与微调所有层
我们不必对模型每一层进行微调,因为神经网络的较低层捕捉到的基本的语言结构和语义是通用的,可以在许多不同的任务和数据集中发挥作用。
因此,我们仅微调最后几层(靠近输出的层)就够了,这些层更具体于细微的语言模式和任务特征。这种方法在计算上也将更加高效。
为了准备进行分类微调,首先我们冻结模型,即将所有层设置为不可训练:
for param in model.parameters (): param.requires_grad = False
然后,如图 4 所示,我们修改输出层 model.out_head :
torch.manual_seed (123) num_classes = 2 model.out_head = torch.nn.Linear ( in_features=BASE_CONFIG ["emb_dim"], out_features=num_classes )
注意,在上述代码中,我们使用了 BASE_CONFIG ["emb_dim"],它的值在 “gpt2-small(124M)” 模型中为 768。这样做的目的是为了让后续的代码更加通用,相同的代码也能处理其他型号的 GPT-2 模型。
新的 model.out_head 输出层的 requires_grad 属性默认设置为 True,这意味着这是模型中唯一会在训练期间更新的层。
从技术上讲,只训练刚刚添加的输出层就足够了。然而,我在实验中发现,微调额外的层,可以显著提高微调模型的预测性能。
此外,我们将最后一个 transformer 块以及连接该块与输出层的 LayerNorm 模块设置为可训练,如图 5 所示。
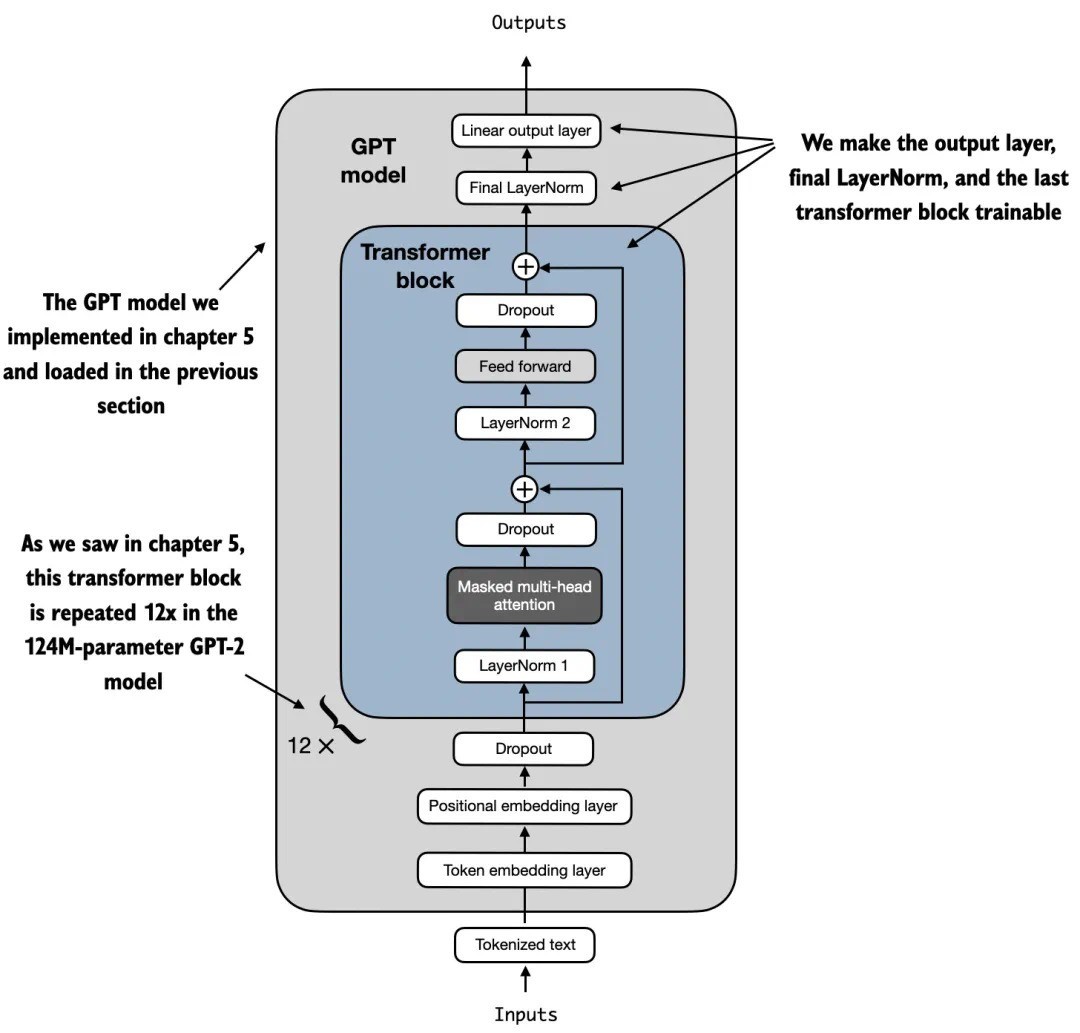
图 5:用我的步骤开发的 GPT 模型包含 12 个重复的 transformer 块。除了输出层,我们将最后的 LayerNorm 和最后一个 transformer 块设置为可训练,而其余 11 个 transformer 块和嵌入层保持为不可训练。
为了做到这点,我们将它们各自的 requires_grad 设置为 True:
for param in model.trf_blocks [-1].parameters (): param.requires_grad = True for param in model.final_norm.parameters (): param.requires_grad = True
尽管我们添加了一个新的输出层,并将某些层设置为不可训练,我们仍然可以使用这个模型。例如,我们可以像之前那样输入一段示例文本:
inputs = tokenizer.encode ("Do you have time") inputs = torch.tensor (inputs).unsqueeze (0) print ("Inputs:
